Jeff Szczepanski, COO, Stack Exchange
In every successful technology businesses Jeff has worked in, the key challenge has been understanding how to scale technology and when to tackle the technical debt that inevitably accrues as a company runs ever faster and faster in pursuit of its business objectives. Jeff draws on his experience to help you understand what challenges emerge as a company moves from a Developer Centric environment to become more business focused.
How can you get the business people to have influence on a developer centric environment? How can you manage the challenges that marketing will present?! What principles can you apply to be aware of problems early? How do you trade Agile Practioners vs Architectural Astronauts in a fast growing business? What are the technical debt trade-offs, what problems can you buy yourself out of? What problems will kill you if you don’t move now?
Slides, Video, AMA & Transcript below
Slides from Jeff Szczepanski’s talk at BoS USA here
Video
AMA
Learn how great SaaS & software companies are run
We produce exceptional conferences & content that will help you build better products & companies.
Join our friendly list for event updates, ideas & inspiration.
Transcript
Jeff Szczepanski, Stack Exchange: Ok. First of all, woah! It’s way more people in the room standing down here looking up than sitting back there looking down this way.
As Mark mentioned I’m tall Jeff, or Jeff Szczepanski at Stack Overflow. I’m imagining some of you people in this room may be familiar maybe with stack overflow. Maybe a show of hands? Yes. How many people used stack overflow this month? This week? Today? Have it on your browser tab right now? Yeah, it’s pretty crazy, right?
Like Stack Overflow, 30 million monthly unique visitors now. Let’s see, at this time of the day, approaching lunch on a weekday, there’s probably 100,000 people on the site right now, actively looking through questions. We’ve just passed 10 million questions not long ago. It’s pretty crazy and when you consider our stack exchange network, the broader network of all the different sites, 150 or so different sites on all the different topics beyond the programmer site of stack overflow, we’re doing over 100 million monthly unique people now worldwide which seems pretty crazy. It puts us in the top 30 or 40 of networks worldwide on the internet. So that’s pretty crazy! Unfortunately, I can’t take any credit for any of that. I’ve almost nothing to do with that part of the company and as COO my role day to day is sort of the dark half of the site or of the network in terms of basically trying to turn us into a unicorn and taking all that money we raised in DC, $80 million or so and turn it into an actual profitable business. So really, the monetisation of the network is really my day job although before coming to stack overflow, I was co-founder and CTO of a VOIP products business. And so spent the first 20 years of my life building software and scaling applications, millions of lines of code within the team and across all the products and the product line and really doing that over 10 to 15 years scaling period of continuous build out and growth of the product line.
So the talk that I’m gonna do today is obviously more centred around that stuff. As Mark mentioned, I actually did a talk in the business of software in the UK last year and that one was called the developer’s guide to scaling sales. And the idea there was that obviously business of software, you have a lot of people with software background, sales can be a little bit of a mystery, so I put together a talk to talk about basically as a software developer of somebody familiar with running software teams, what do you do and how can you think about that side of your organisation in terms of scaling sales.
And I guess the really interested feedback from that talk, because like half of the audience and people that felt with me afterwards, asking me all kinds of questions about applying this software development technique to scale in the sales organisation and which is what I expected but then unexpectedly the other half of the questions I got was like wait a minute, talk to me more about how you stabilised and scaled software development. In other words, the developer’s guide to scaling software! So that’s where this talk came from and that’s why I’m here to talk about this a little bit. And the title we came up was this idea of unscaling your technical debt and I think we all have some idea of what that means that we undergo here a little bit just to give you some context about the presentation here and the thinking about what I want to talk about.
How do you know if you’re suffering technical debt?
You have some familiarity around this, do you experience regular schedule slips going on and it’s hard to even make a schedule and do you even have a schedule? Is there a frequent need to refactor things? Are you going back and rewriting code, throwing things away, rebuilding different parts of the code and doing this more often than it feels you should be?
There’s this whole idea about the cadence of the output of the team and how frequently you’re delivering features, how quickly they get to the field relative to when you need them there to move your business forward, just adding new developers to your team, not speed things up or even worse slow things down? Buggy code obviously, frequent regressing, you show new features and you break things that used to work. Problems like that.
Ongoing performance or stability problems? Your applications version of the fail well at Twitter that we’re all familiar with, probably one of the most notorious form of ongoing technical debt. Slow turnarounds or bug fixes. Does it take too long to fix something that looks like a simple bug and people can’t figure out why it’s broke? Can you not track it down? And then bug fixes for your bug fixes. Ship a fix, it breaks something else or it didn’t really fix it the way it’s expected. All symbols are signs of what we think of as classical, I think, ongoing technical debt.
So what do you do about this? Simplest solution, rewrite!
Thank you, David! I actually revamped part of the presentation here to talk specifically about some of this stuff. This is really good context to talk about the topic in here and yeah, and so the question here is rewrite, that’s obviously the most brute force to do it and what was interesting about David’s talk by the way was made me think a lot about the rest of my talk actually and the context that this sits in. What was interesting what he said is that he was claiming that he didn’t suffer from technical debt, in other words they had none of the problems that I had talked about on the slide, and I was thinking about that and saying wait, rewrite? Why is he doing that and was he really suffering from technical debt or not? I’m gonna claim that he was actually, at least in the way that I think about technical debt.
So there’s another kind of technical debt.
The part we talked about before was essentially what I consider classical technical debt, the kind we think of that comes from sub-standard coding practices or less than ideal stuff, but the other kind is the kind of technical debt whereas David talked about, you want the clean sheet, you want to be able to rethink the things that you’re doing in your product you obviously have to be throwing something away as you readapt the product. But the technical debt is going on here when you think about it is you’re going from version 1 to version 2 and 3 of your software, how much code are you actually tossing away and rewriting things and how much of that tossing was actually avoidable or unavoidable. So David is a smart guy, base camp they make the right product, I’m sure they looked at it and said it there’s clearly gonna be some level of rewriting going on but it does force you to think about it a little bit how much of that was avoidable and unavoidable. So a way to think about this I think is this idea that you’re trying to keep your code base; the iceberg analogy here, you’ve got features and functions and a code that delivers features that the customers are familiar with under the directory directly interacting with. This is what I’m gonna call the above the water features.
Learn how great SaaS & software companies are run
We produce exceptional conferences & content that will help you build better products & companies.
Join our friendly list for event updates, ideas & inspiration.
There’s no questions that if you change the metaphor about how you change the UI, the customer is actually directly interacting with the interface of your product and there’s gonna have to be some running going on and you have to throw away some stuff, but there’s also stuff in the product that under the water in the analogy here, that’s going on behind the scenes that I’m gonna claim is the stuff that hopefully is where the majority of your values are coming from, from your product. These things are actually going to be a little bit more sustainable and there are things in your code base, at least ideally, a line with thinking about how your system is designed in a way that matches the valued proposition or your differentiation and position in the marketplace to your customers. In other words, is the code base the bulk of it, designed in a way that’s abstracted and it’s actually carrying value relative to what differentiates your codebase or your product in the marketplace. And so, when you look at this, what you’re trying to think about, I think going forward in terms of eliminating this strategical technical debt is how much of what you’re doing in terms of how you develop your software, being pushed below the water with the iceberg here and how much necessarily must be above the water.
So I’m going to come to a little bit of a more formal definition of what I mean by technical debt and it’s this idea that technical debt is anytime you have this misalignment of what is easy to do with your codebase and your data structures compared to what you needed to do to be more competitive in the marketplace. So low technical debt is when you can quickly adapt what you have to what you need to differentiate your product on an ongoing basis to be separated in the marketplace. So I’m gonna question the idea of, you know, how much of it is inevitable and how much is not essentially.
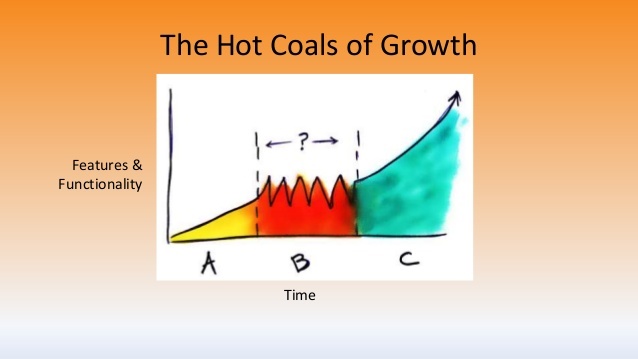
So there’s another take on this. In terms of how you look at this, there’s what I would call the hot coals of growth. So when you think about technical debt in your product, in this whole idea of scaling and how that relates to your scaling, to move your business forward and operate in scale, you need to have essentially, David mentioned yesterday in his presentation, that how many new customers are gonna sign up when he ships basecamp 2, when they ship that, and I guess the third version is coming out soon and it’s this idea that the features are mapping directly to your ability to penetrate into the market further.
If you’re operating your businesses at scale, it’s pretty easy in the early days when you have a couple of smart programmers and they’re doing quick one off of new features and shipping stuff but as your business keeps getting bigger and bigger and your product gets more and more complicated, inevitably there’s gonna be some level of this hot coals phase. And it happens not just because of sort of the classical forms of technical debt, but it’s because your – as you get more scale, the market around you is starting to change and put more demands on your product.
So I call this the evolving bar of quality.
So let’s assume that you ship software and the reuse of bits that Rich talked about yesterday and your idea is to get as many copies of this out there as possible. If you assume for a moment that your code base is static and given a set of features there, just by virtue of the fact that you’re signing up more and more customers there’s more and more demands being put on your software and in essence, technical debt is accumulating on your own, without doing anything. One way to look at this is the 80/20 rule evolving into what I show here as 99/01 rule.
At the beginning when you’re in the MVP phase and you have a small number of customers, it’s pretty easy to do these trade-offs and say that’s good enough for now, I will worry about these other cases later. And in the beginning when you’re in the early adopter phase and people love you because you’re a novel little product it’s pretty easy to hold water but as you get tens of thousands and millions of customers and users using your site that 80/20 rule just doesn’t cut it anymore. And if could be – if you have one thing that affects 1% of your user base, in the case of Apple, we’re talking millions of users. So this is one of the things that’s incurring technical debt and you have to realise that this is a had win in terms of what you are fighting against with your product.
The other factor that’s going on here in parallel with this is what I call the customer compelled versus market focused thinking. And when we think of dot release and some of the stuff that Rich was talking about yesterday with sales team feedback needing another feature and things like that. It’s this idea that we can all see it and David talked about it too and this is the customer compelled nature of what you can do in the context and the current solution and where your product needs to go in the longer term. So I talked about a technical debt that comes from not just being customer compelled and the actual definition of your features but even getting back to this iceberg analogy of how your entire system is being architected. In other words, is there somebody on the team thinking about how the architecture and systems and services behind your product are evolving and staying aligned or not with the valued thing that is fundamental to your proposition to your customers?
So when we go back to the rewrite analogy in basecamp, I raise a general question here of how much of the rewrite was actually necessary? The first thing I will say in the case of basecamp built on inner rails, obviously all that stuff didn’t get rewritten, right? And so there was a core tools or your compilers, there’s the common libraries and stuff like that and obviously all that stuff is staying constant and is having certain programmer value, but then there’s also stuff in the product that’s part of delivering your valued proposition and maybe in the case of basecamp and a lot of products, one of the core value things is actually the structure of the data, the customer’s data. And sort of your – if you want to achieve scale, moving customers along the line there and bringing their data with you is just as important as scaling and everything else. And I think at least in my experience what David talked about with basecamp was that the new version coming out is gonna go after a whole different set of customers and that’s great! If you’ve got a really big market – and you’re still relatively taking a small percentage of that, there’s a land grab going on with each new releases, you’re bringing in new customers but if you really want to operate your business at scale, at some point it’s not ok to say we’re not going to sunset these people but you also can’t leave them on the old version, you can’t jettison people and realistically to do this at scale, you gotta think about your product in a way where you can efficiently bring them along with you.
So this presentation then is really about how do we ensure this or some different way to think about it? With the core goal here of that your features and whole product quality and all these ways that we’ve been talking about in the eyes of your customer is moving smoothly and up and to the right, that is really what you’re trying to accomplish here and it’s the definition of technical debt that I’m talking about.
So put in another way, the key to scaling your business is bringing your customers and all their data along with you through your road map. And that’s really what from an engineering team perspective your goal really is in terms of what you’re trying to achieve. And obviously in the face of competition, doing this efficiently and effectively because as we know, the developers are always in high demand, things like rewrites may be exactly the right thing to do, I don’t know for sure if it was the best thing to do in basecamp, it probably was. But the question that year and a half that he talked about that they spent, what else you could you be doing, how much of that was truly inevitable and unavoidable rewrite?
Ok, so hopefully that makes some sense in terms of the context you’re trying to put together around this. The next step here is, I guess, we’re gonna talk about software process for a little bit. Sort of a holy wars. The best way in any lunch room table to get developers arguing with each other is just to talk about probably indenting styles or software processes. So, basics. Everyone agrees, right? Agile good, waterfall bad. Show of hands? People think so? Seems like most people. Ok, yes or maybe not. So this is an interesting thing to think about.
Good properties of agile.
It admits that requirements evolve, I think maybe a couple people talked about this yesterday, including David and this innovation around Agile and thinking about like hey, this is a pretty artificial notion that requirements are never gonna evolve. We’re changing things and it’s gonna be perfect. Good property in Agile takes that into account. Encourages regularly releases which allows validation of progress more often. I’m gonna talk a little bit more about schedule and cadence, but an important part in developing quality software in all the forms, meaning keeping the technical stuff to a minimum, regular releases and knowing exactly where you’re at both from a stability and a progress standpoint is really important. The sprints concepts within Agile techniques is really important for driving cadence, in other words keeping the heartbeat of the team moving at the right rate, understanding what that rate is, having sort of mechanisms within the process if you will, to regulate and drive all aspects of that. Closes the loop relative to quality, a really important one. And I mean this in all the sense, the whole idea of the retrospective is really take back what you’re learning, based on how you’re progressing and what’s going on with customers and what you shipped and feeding that back in a nice closed loop process around that, all really good.
Pitfalls
There’s probably some programmers in here, in my experience, talking to a lot of different teams through VC’s. You get to meet with other teams that stay at start-ups, struggling with things, talking to them, this seems incredibly rare that scheduling any period of time out is actually going on in the team and we’re gonna talk about that a little later, and why that’s actually important. Implicitly, my mind encourages feature centric thinking at the expense of good system design. The very thing that we like about sprints and being in Agile and being dynamic is this idea that we’re gonna ship stuff quick and we know where we are and we’re sitting in a room with astronauts and it’s not doing anybody any good but I’m gonna say that a strong pitfall here is this dynamic thinking in effect encourages shortcuts. Lighter specs and documentation and this whole idea, even the slide, why plant or document things too much when it’s just gonna change anyway? It’s software! Definite pitfalls of Agile in my mind.
Waterfall, good properties. Yes, there are some if you are too young to remember the days when we used to program only in Waterfall. Formal specifications rule, this idea that somebody actually takes time and writes down all the requirements of what it is that we’re going to build and it’s doing analysis on those requirements and specifications and it’s actually valuable and helps you to think through the process. As I said in the last slide, Agile tends to short circuit this because of that sort of quick instant fulfilment, MTV mentality if you will.
It emphasising detailed planning in putting together really detailed plans and how you’re going to progress through this waterfall of activities. System design is specifically a thing. In other words we have customer requirements that we gathered, we turn that into specifications and there’s actual architecture and design phase that we go through and people spend a lot of time on how exactly they’re gonna do this in a nice, graceful and efficient way. And then arguably, I’ll say, if your requirements really are well-known and you have a good process capable team of good developers, I’m gonna argue that this is the most efficient way that you can develop software and I think that’s why we started with Waterfall, it’s intuitive, it’s efficient – with the caveat that requirements are solid, obviously. And they’re not. So requirements are never perfect and this again is where Agile really shines. Waterfall has this idea that requirements are evolving, a little bit tricky.
Encourages long serial release cycles. This is the same idea, this idea that you’re gonna spec everything, design, build and test everything. This is really painful potentially for any of those things aren’t quite right along the way. So problems get discovered late and ultimately costs of errors are super high, especially the earlier they were in that starting with requirements and this is where I think Waterfall gets its bad name. We don’t have the requirements upfront well enough, everything downstream is kind of screwed, not a good way to do software development.
But we go back to the upsides and downsides of Agile, I think you’re gonna see if you compare these two things that in a sense, the pitfalls of Agile are pretty much the strengths of Waterfall and the strengths of Agile are pretty much the pitfalls of Waterfall. And they’re the two sides of the same coin when you’re thinking about trade-offs and how you’re approaching your software development. If I was an expensive consultant with training classes, talking about software process, I’d trademark the idea of the Agile Waterfall Continuum. And what I’m really trying to say here is when you look at these pitfalls and strengths of the two processes, then what you’re really trying to do when you’re looking at the different aspects of your team and the different systemss you’re building, there’s really this continuum going on. And there’s good properties and bad properties, the way that software development moves and what you’re trying to do in a sense you minimise technical debt going forward from a process standpoint and how you’re running the teams is really you’re trying to set a dial on this Agile Waterfall continuum on the practices on how you’re approaching various things.
What are the variables going on? It’s pretty intuitive, I think, but I’m gonna go through them here. The first and most obvious one is the length of the release cycles. And Waterfall, you have these very long typically releases because you’re going through this very serialised process of recording and so on down the pipeline tends to lead to really long release cycles but there’s nothing inherent in Waterfall that says that you have to have long release cycles. But there’s nothing inherent in Waterfall to say that you have to have really long release cycles. Back in my day, we had a 12-week target release cycle, still operating Waterfall and somewhat Agile way to do that.
What’s your clarity and confidence around customer requirements?
Are you in the early MVP phase when you’re just trying to figure out what the heck is someone even going to buy this thing? Do we know what it needs to do? Do we know how it’s going to work? You’re definitely gonna be more on the Agile end of the continuum. As you start getting bigger, more people on the team and more customers in the field, you start knowing a lot about what you actually need and you know, again, David talked about it yesterday in the rewrite, they can sit down for a year and a half and presumably with a bunch of requirements around, how they’re gonna revamp the product, and I’m guessing at some level, Waterfall process needed to go on in terms of understanding exactly what it is they’re gonna build to have this big release coming out soon relative to shipping this great new version of the product.
And what we’re doing is we’re playing with these variables in terms of how you think about or approaching the problem. There’s depth of the system complexity. We’re building a basic straight database web app that’s just hitting tables on the database and we’re putting a space craft on the moon or something. There’s wide ranges of complexity and I’m gonna make the argument that as things get more complex, you got to go towards the more rigid and structured requirements analysis approach on the Waterfall approach than you need to on the Agile end of the spectrum.
How catastrophic are defects?
Is somebody gonna die if you ship a software and the blood analyser doesn’t do its thing? Or again, is it a database app on the web? These sort of dictate being in a different place in the continuum. How big is the software team and the customer base? Again, I’m gonna make the argument that as you get larger and larger scale, getting more and more structure in less and less sort of strategic technical debt within your code base and data structure so you can move customers through their roadmap is gonna lead you to much longer range, strategic types of thinking that lends itself to Waterfall.
So another way to look at this – this kind of gets back to the iceberg analogy and stuff that’s above the water and below the water. With the blue line being the waterline and this slide here, but the Agile end of the thing is where you’re doing requirements discovery and validation and incremental feature delivery. You’ve got a whole lot of code, almost all of it it’s the same, you just define those things, punch them out, code them and get them shipped. You want to be at the Agile end of the spectrum for that.
Simple systems close to the UI, typically with that I think this is probably the case of Basecamp to some extent. A lot of their code I’m sure it’s in the UI and interacting with the user and the metaphors. That’s the stuff that’s gonna need to be reworked or rewritten and the Agile part of the spectrum for those phases makes a lot of sense as well. Anything is really your progression of your dot releases.
But as you get more strategic, you’re gonna start moving towards the Waterfall side of the spectrum in terms of trying to keep your code base aligned with what’s valued by your customers and maintaining that continuity from release to release, a major feature version. So this is the development of your core services, it’s all the complex stuff that’s as far as the UI and again I’m gonna claim that when you’re thinking about the objects in the subsystems in your product, you’re trying to get as much as you can below the waterline to get the technical debt to a minimum because you wanna keep that aligned with the things that are actually valuable to your customers and that the code in a sense it’s aligned with and almost thinks if you will, the way your customers would value things that you deliver.
Ok, so visualising this and trying to get a little bit more practical. I think we spent a bit of time here, all on the sort of academic way of thinking about this from a process standpoint and the definition of the terms around technical data and what I mean by that in its various forms. Picture is worth 1000 words so I was thinking about this for a little while and one thing dawned on me and I know people have seen this before. This is the crazy hot matrix of dating! On the one axis here – I think I got my laser pointer. I don’t know how many people have seen this before, but I will go through this quickly just so that you understand the analogy in my next slide. But on the y axis here we have the crazy scale. This is sort of how crazy is the prospective dating partner or emotional availability of that person, those kinds of things. The scale here goes from a 4 to a 10, because everybody is at least a little crazy and 10 up here it totally crazy. On the hot scale, this is the beauties in the eye of the beholder here and the idea is whatever you value in terms of hotness here, we’ll call this maybe a 4 or 5 ½ on the scale in the sense everybody to the left of this line here are people from a dating perspective you’re gonna want to avoid. And what we have here is this line which is like the crazy/hot matrix’s axis here. And as you get up higher on the hot scale and lower on the crazy scale, you have the friend zone or the fun zone. People you’re gonna date casually, go out and have fun with. Above the line up here is the danger zone, these are people starting a little too crazy. You’re gonna be attracted to them, cause they’re up here on the hot scale, but they’re a little bit too crazy. And then you have the dating zone, people you’re gonna bring home to mom, not very crazy but definitely on the hotter end of the scale and the low here is the marriage material point. People that are hardly crazy at all, but definitely on the hot scale, by your definition. And on the bottom corner here we have the unicorns. These people don’t exist. If you’re that hot, you gotta be at least a little crazy. Yeah. This are the prince charming or the unicorns or maybe Angelina Jolie or Brad Pitt I guess. I don’t know.
Anyway, this is the crazy hot matrix for dating. So what’s the similar way of thinking about this from the Agile Waterfall continuum? A little bit more complicated cause software is more complicated than dating, sometimes. Let’s see which one is which here! Ok, so what’s going on in this one? On the y axis here, we have the Agile Waterfall continuum I’m gonna call it. Up at this end of the scale, pure Waterfall. Danger, danger, danger. Crocodiles and alligators up here. Likewise, at the opposite end of the scale, I’m gonna argue, this is where like extreme programming is at to some extent. Crocodiles and alligators are down here too, pure Agile in its form and I’m gonna argue that you got to stay away from that side of the axis as well, both danger zones.
And the other axis here we’re talking about system complexity here. This is a combination of whether you’re putting people on the moon or you’re shipping database crud applications, that kind of thing, it’s part of this but it’s also just part of the scale of the team, as you get more people down there and they want more code, more things are going down and more features and you’re gonna be pushing on the area of complexity or even maturity of the code base if you will. And so, when you look at this chart here, I’m gonna claim you got this quadrant over here, I’m gonna call this architecture or astronaut zone. This is the danger zone in the sense what you’re doing is putting lots of Waterfall in a really simple system. It’s this over abstractive and we’ve probably all seen this before, classes that encapsulate other classes that are all virtual and empty and different things going on in there where bottom line if you want to flip a pixel on it or put a row in the database. So you want to stay out of this zone over here. The other one is when your system is getting more and more complex, bigger team, but you’re staying in Agile to all the ideas that I’ve been talking about before. I’m gonna call this refactorville, rewriteville, bug city. All bad areas to be for the most part. So we really want to be in this quadrant up here in the top right, right or the lower right as you’re looking at things like essentially the complexity of your system and how mature is the codebase and the size of the team.
Learn how great SaaS & software companies are run
We produce exceptional conferences & content that will help you build better products & companies.
Join our friendly list for event updates, ideas & inspiration.
I divided these up a little bit. I think I would typically argue that large teams generating lots of code or maintain large code bases over long periods of time need to be more in the waterfall end of the spectrum overall from a core systems perspective, certainly if not even pushing into stuff that’s getting a little bit closer to the customer, functionality wise, in UI wise if you will. Smaller teams can be pretty stable over here being highly Agile in the early life cycle of the product, I kind of broke out just to give you an idea, I think you’re gonna push more Waterfall as you get like an embedded systems development. The cost of failure is extremely high, requirements can be defined in advance and then you wanna do and get all the benefits of the more Waterfall like approach, similarly this is sort of the simple corporate applications, access, development kinds of things that are going on that can be over here or typically need to be cause it’s probably less sophisticated teams doing relatively straight forward software development. So that’s the graphical version of this thinking.
The next phase here that I want to talk about is – I keep getting these confused. Sort of a practical self-assessment kind of thing, here we have the Joel test. This is – I gotta throw this one thing in my slide, cause Joel is my boss. I talked about Joel and any good software presentation is gonna mention Joel and this one we’ll make the argument. This is actually a complete misuse to be clear of the Joel test. I’m guessing a lot of you are familiar with it. If you’re not, it’s in Joel’s book being smart and gets things done. Of course you can just google it. This is many years old and the actual purpose for this Joel test originally is – actually Joel would tell you that this is really intended actually for somebody who is a programmer looking for a job and you’re gonna make a decision of whether or not this company takes software development seriously and as a serious programmer, is this a place where you would want to work? These questions were intended to get through an interview with the person interviewing you, to make sure that you thought this would be a valuable place to work.
But I think in our context here, when we’re thinking about sophistication of our software development processes, how the team is structured and to Joel’s original point, how serious do we take software development? The Joel test is actually a really good place to start, I’m not gonna go through all of these, but I think if you read on the slide here or recall the test from memory at some level, these are all really important things that contribute to or indicators relative to your process sophistication as a software development team. Maybe one thing to add is some people have been asking Joel to update this for a while, what’s the more modern version of this? Because of its original purpose, Joel said that there’s no reason to update this, it’s still as valid as it ever was and I fully agree with that actually. These things are still so core to fundamental to certainly operating teams that scale – all these things are gonna be important. Small teams that are really good, can you get away without doing these things? Sure! But if your goal here is to really build a unicorn sized business or at least operate at scale, you should have a pretty good answer towards the yes direction. Pretty much everything on this list.
But that’s not quite enough, at least in my mind in terms of things relative to the technical debt side of the equation that we’re talking about here. So I’m gonna basically propose a few additions to the Joel test in terms of things you should be thinking about that help you stay away from the alligators on both ends of the scale and help you think about ways of managing your technical debt.
The first one is, do you document your services and major modules? As I’ve said before, I think in Agile places, documentation and writing things down, going through formal process of designing things and thinking about how things are built is the thing getting short changed. So I think this is another really good addition to the test and what do I mean here? I’m talking about Word documents or something that’s actually written down somewhere, at least 1 page or something that talks about exactly what is the role of that particular service or major module? Why does it exist, how does it align with things that are interesting to your customers? What are the implications of violating certain design assumptions that were made when that was built? Just the act of actually writing this stuff down or forcing somebody to write it down is gonna make you gain a lot on this, even though nobody reads it or keep it up to date. But I would argue that ideally, you should be doing all that.
And really another thing that’s core to this, is really avoiding the tragedy of commons. I see this a lot of this on Agile teams, things are very dynamic, things are moving around. People are moving from project to project or the team to team or module to module. And there’s this tragedy of commons that exists that no one person owns the conceptual integrity around various parts of your system. So I’m gonna claim that anything, certainly at a major level, but really all your code, any module in the application needs to be owned by somebody. Somebody has got to have a strong sense of ownership over that particular thing. This needs to be their teddy bear to use the analogy.
And the teddy bear in the sense that not only as a developer really having a sense of ownership of what its purpose is, what it’s doing what does it encapsulate, what does it mean for that to be developed right, no matter how many people are working on it? But also, you know, how it aligns with what customers actually need and how that particular subsystem or server module actually does something that’s useful and beneficial to the customer on an ongoing basis, it’s independent of any particular given release. These are all the things that are below the water, from the iceberg perspective.
Very similarly, document all your data.
This one kills me all the time, even on our own company when we talk to developers about this – is there a clear definition and a strong invariance around what these data tables are actually supposed to represent from a customer standpoint? Is it a project or a job listing or a question or answer or post? And what does that really encapsulate? What assumptions were made? Why it was architected that way or designed that way? And something written down about every single one of these fields, exactly what they do and what they mean in the various states. This is crucially important in my mind. If there’s one thing that can get you fired in my development team it – fragrant violation of this kind of stuff. Super, super critical of keeping a really good definition and what everything is doing in the database. And maybe more importantly, back to the tragedy of Carmen’s idea, there’s an honour in here to actually reviewing changes to the data tables. If someone is going to go in and make an edit to it, do they understand what they’re really doing and what this table is trying to encapsulate? What do you do to keep the technical debt out of it? Things that lead to bugs and instability and stuff like that when there’s not a clear definition of these things.
Another addition at scale. Do you enforce a coding standard?
Do you even have a coding standard? This is where I get a little bit of debate on, people don’t like this one for various reasons but it ties directly in my mind which is do you do code reviews? Seems like this is absent on many teams, as you start to scale, this becomes crucial because how else do you tell whether the people you hired and have working in the team are actually doing a good job? Like one of the original questions on the Joel test is do you make people code in interviews? Once you hire them, are you looking at what they’re developing? The compiler shouldn’t be the only thing looking at their code, just because it compiles and it can do something, doesn’t mean that it’s doing it well or it’s written well or it’s efficient. And it’s not only inherent to the coding standards for the sake of them, but it’s just is that code constructed well? Are they a good developer? And everybody learns and we’re always embarrassed to look at our own code from 1-2-3 years ago. But are you putting processes in place, essentially, to make sure that people are – from a skillset standpoint are going up and to the right in terms of the code that they’re generating?
Another one, do you track bugs back to your source?
One of the original questions in the Joel test was, do you have a bug database? But again, at scale, as things get bigger, what do you do to close the loop on quality? There’s a lot of good research done, probably back in the 80’s now I’m guessing. I know a few read code complete, Stephen Connell’s book, which I highly recommend certainly for the coding level which the book is all about, code construction. Code construction techniques, the studies were done…basically he figured out or realised that bugs cluster up highly. They cluster up typically in a specific function within a big module or something like that and what the intuitive understanding on what’s going on in terms of bug cluster is somebody didn’t have their shit together the day they wrote that function and you can’t test quality into a product. The code works right because somebody understood what they needed to do so they coded it right the first time and when bugs are cropping up, the basic argument there is that just because you discovered one, doesn’t mean you discovered them all and there’s probably something more fundamentally going on. And part of this is the developer being diligent, to go back and fix the bug and be like what else did I miss? But this is the idea of I’ve got a process in place that can catch the thing and make you realise we’ve been back here twice or three times back in this function of module. What’s going on? Why did we have to fix multiple bugs? Who didn’t have their shit together that day? And then the other one I think from a team scaling and management standpoint is, is this clustering up my programmers? In another words, is there hints that somebody needs some development in terms of better design or coding techniques. Coding skills, I guess I should say.
And last but certainly not least, do you define deadlines and hit them?
In other words, as a team, can you make a predictable schedule? This one I get lots of pushback on from talking to lots of people. For me this is crucially important and I spent a fair amount of time on this one because I think it’s super important relative to the software. Scheduling sceptic out there? This is the form I usually hear it in. Why spend time making a schedule we’ll just end up being missing…we will put all that time into the building functionality. I don’t know if that’s sort of contradicting to anybody, I look at it this way. Why bother digging that foundation? You’re just increasing the size of the building that I need to build. Schedules are crucially important.
Why? As you scale, it’s not just about outputting the software and features when you get to it. Sales marketing, customer support and the customer themselves care when things will ship, whether it’s coordinating the PR around the launch, for a trade show or things going on in the real world, whether it’s in the company or out in your customer base, schedules matter.
Another reason its good, roadmap decisions depend on good cost/benefit tradeoffs in the roadmap. Not only is this feature worth it, but do we need to do it this tactical way for now before we have the strategic solution? Or we’re gonna wait for the strategic solution. To make that tradeoff you need to know how long it’s gonna take and you need to be able to do it accurately.
These are sort of the obvious reasons as to why scheduling is important, the slightly subtler ones is that how else can you deterministically evaluate the performance of your developers or your development team? This one is really important I think because how long should the software take? If you got a 7-8-10 or 15 features to do and we don’t sit down and say how long it’s gonna take, how do I know that that’s a great amount of time for the take. In other words, having the schedule there is to be clear, defined by the developers themselves rolled up from the bottom, but this idea that part of being process stable and being good at developing is this idea that you can build a predictable schedule. So if you want to evaluate a new developer on your team, not only is it about the code reviews and looking at what they develop, but it’s also this idea, well I had him to do this x,y, z and it took them 3 months, is that good or bad? The best way to find out is before they start, ask them how long it’s gonna take and estimate it. Now you know if it’s good or bad or whether that’s stable and predictable within your development environment. So this is super important in my mind. It’s just the way to put a quality control loop around how software development is being done.
And the other one I will argue is to be able to do that and do that well, predictability is a symptom of high quality software development. You’re not gonna be predictable relative to the features, bugs, reliability unless you actually have a really high quality software process going on. So this idea that you want to use the scheduling as a tool to combat technical debt in all its various forms that we’ve talked about is super important. So the key point here, leading to the business punchline, having reliable software schedules is crucial to the efficient scaling and continuous output of your development team. In a sense, good schedules is good business.
Schedule slips
Some people talk about downsides to scheduling and the types of negative effects it can have and it’s very important to take that into account. Just like the Waterfall Agile Continuum, there’s tradeoffs for all these things. Schedule slips, think of them as a learning opportunity, estimation at the core team level, different things beings shipped, it’s a scale and you have to develop that in people. So obviously when you’re missing the schedule and understanding why and getting people better to do those things is important to be able to maintain all the upsides to what we’re looking to do here.
It’s always better to do structured slips than the cramming stuff. People, managers, executives in the company – must ship, must ship! Keep everybody’s feet to the fire. Bad shit starts to happen when people are getting desperate and trying to slam it out the door. Unless somebody is gonna die or the company is gonnna go bankrupt, you wanna do structured slips. You’re not gonna go it perfectly every time and I think when you get really good at all these different ways of managing technical debt, you will get really good at estimating schedules. We were able to get very good at it. It all works and we’re in very consistent deliveries. But when you’re in situations where your behind schedule, somebody has got to be smart enough to do the structured slip. So you don’t start getting all the negative consequences of cramming it out the door.
And then the other one here is this idea on teams delivering sub-systems of modules. Each team should have what I call an anchor and a rover. The anchor, which is typically your team lead, for particular modules, we’ll talk about it more in a minute, is the person ultimately responsible for making sure that everything gets done. They’re taking the strongest ownership around getting the thing shipped and they are the one that’s gonna be making sure all the ducks in a row, relative to what everybody is doing. But then you also want to have this rover on your team. Your schedule is probably determined from some sort of critical path of how long it was gonna take. You might not always have somebody on your team that is not scheduled to be 100% on there, specifically designated as the rover where the estimates are never perfect so if you wanna maintain tight schedules, you need to have some place for the slack to go when you inevitably have unforeseen things happening. And this again is all about the quality and consistency of the output of your team. You got to have contingency built in. And in my mind, the best way to have contingency is not to pad the schedule in a calendar sense, cause that’s gonna slow you down. What you want to do is just making sure that not everybody on the team is 100% committed.
So putting it all together, what does it all mean in terms of team structure? In other words, what do I advocate in terms of how to think about structure and development teams? Especially at scale. You know, when the team is small it can be very ad-hoc, your basic typical scrum team – 5 or 7 people, developing pretty easy. What do you do when the organisation gets bigger? Where do you start thinking about specialisation and focus for various people? There’s lots of different skills at play and that’s the thing to remember here. Discovering, developing and finalising the requirements, system architecture & design, estimation of tasks, project management, the maintenance stuff, everything is all in there. Lots of different things going on so this is the one thing that keeps your mind on it, there’s lots of different complicated things.
And the goal here in a sense is to have people, each developer good at a lot of those. And this idea that performance doesn’t equal results. In other words, it’s like a football game that you play – American football style – that’s at least what I have in mind. But if you can play it really well and still lose the game, you can win the game and not play it very well. This idea that part of what you’re looking to manage within the team is actually looking at the performance and skill factors of each individual person on the team not just hey, did we make the schedule? Schedule slips and bugs and refactors are all canaries in the coal mine and ok you have problems going on, but if you want to fix those problems, it’s not about forcing people harder or hiring more people, it’s about getting back to the core skills that are really at play and making sure that those are being developed in the right way for everybody on the team.
Other thing, we desire steady cadence and continuous output. What do you do with the structure around that? Paying attention to motivation and morale. We’re looking for this continuous process that can’t be death marches and fits and starts, faster and slower. You want a nice case, everybody is efficient when you keep them warm and comfortable and consistently delivering and then of course the whole idea that you’re empowering people not to manage and direct them. So these are all the different things that goes into, at least my way, to think about how you structure a software development team.
Three key roles I define in terms of the fundamental things:
- The obvious one is the developer, developing code, possessing hopefully a bunch of these different skills that I talked about. Those are the people being observed if you will and you’re looking to motivate and send in the the help to become better programmers.
- You have the team leaders that act as the players and the coaches. These are the people that are probably the lead, if you want to call them the dev leader, the person in charge of the project, the anchor that I talked about in the other slide. I say the team leaders typically are – we’ll talk more about them and then the engineering managers who are ultimately best put to skills development. So the team leader, who are these people? Walking personification of your ideal developer. When you say great software developer, who in your company comes to mind? Those are probably the team leaders, the ones that enjoy the mentoring. Their role on the team is usually gonna be driving cadence faster, usually the scrum master, sort of in charge of the morale on the team, this idea the anchor, they are the ones helping everybody emotionally and logistically get through each one of the sprints and moving the progress of the codebase forward for that particular module system, whatever. They’re responsible for the team meeting its deadlines and in charge of the quality of what’s being built. They’re the person, when I talked about documentation, who owns this module and is responsible for it, usually it’s a team leader or dev lead in this kind of role as I defined it. Again, they are a player and a coach. It’s part of it being the ideal developer and role model to follow and mentoring other people. They’ve got to be doing code and not only keeping their hands dirty and helping the team being up-to-date, but also being able to productively mentor people on the team. But they’re not really in charge of skills development. I look at them as the eyes and the ears for the engineering management that’s gonna be doing the longer term development of the people. This is really about getting through each sprint and each release, doing it as efficiently as possible, being in charge of that cadence and pushing the team through, not so much about fixing bad developers and the good ones or whatever.
- That’s where the engineering manager comes into play. Again, primary responsibility is skills development. I’m gonna advocate that they are the actual boss or the line manager of all the developers on the team. Different companies are gonna have different ratios here. Teams start getting big for 6-7-8 developers, you’re probably breaking stuff up at this decimal. Engineering managers, they are gonna probably be covering 15 or 20 developers maybe in a lot of companies. You can work with 15 or 20 engineers in terms of their long term career path and their ability and skills as a developer. They are to remove operational barriers and keep them efficient so they can focus on the code and the codebase and the technical aspects, engineering managers are probably warding off senior executives and COO’s bitching about something. They’re working on their longer term horizon and thinking sort of strategically relative to the overall competence, process capability of the development team and all the individuals on it. This is gonna specialise too as the team grows, you’re gonna have people that are more operationally, acting in terms of their management sense and dealing with the rest of the organisation around the development team. Could be in terms of tools and tools development and the environment everybody is working in and what’s the latest trends, what are we trying to keep up with and all that, in combination with people that will probably be more specialised to mentoring the developers and make them better.
This role separation, people ask me about this a lot – trying to understand the difference of it. The best analogy I can come up with here in terms of how these roles divide up is in Nascar racing or any kind of track racing where the team leaders are actually with the cars on the track or the developers, the team leaders of the track, racing pit crew, making sure things are going around the track at the right rate and we like the way things are running within the context of the situation we’ve been provided.
Whereas the engineering managers in the skills development sense is more about after the race. What happened after the race, what are we doing, how good is this car, does it need a suspension overhaul? What kind of things can we tweak and develop over time to make it better for the next race? Role separation, hopefully that’s a bit helpful thinking about that.
On the team, the cadence and the morale aspects are mentioned already bottom up estimates are really important striving for that continuous and steady output. Ownership of goals within the team and ownership of the schedules and the quality things, coding standards and compliance and all that. But no death marches and the structure slips that we talked about. Using peer and social pressure versus edicts. Programmers don’t like to be told how to do things, but setting up cultural norms of what’s expected within the developers is super valuable in terms of getting compliance with the things that you want to get done there. Of course, merit and not tenure based advancement within your team, nothing pisses off developers more than putting incompetent people in charge of things they shouldn’t be in charge of. I guess that pisses off everyone, but developers are particularly cranky about that.
So in summary, minimising technical debt is about matching your code base and your data to your market. Predictability highly correlates to quality of what you’re developing and your ability to keep technical debt to a minimum. Understanding that performance does not equal results and the ultimate goal here is developing a suite of strong skills in each one of your developers.
Thank you!
Learn how great SaaS & software companies are run
We produce exceptional conferences & content that will help you build better products & companies.
Join our friendly list for event updates, ideas & inspiration.